前后端联调之跨域问题
本地计算机同时起了 前端 和 后端 项目,想要进行联调。
- 前端项目为 vue 3.0,端口为 5173
- 后端项目为 Django,端口为 8000
此时出现了『跨域』问题,需要解决。
本地计算机同时起了 前端 和 后端 项目,想要进行联调。
此时出现了『跨域』问题,需要解决。
van-cell__value 设置 min-widthvan-cell__value 本身是右对齐,但是换行之后,最后一行需要左对齐而不是右对齐,解决方法如下面的 span 样式1 | .address-cell { |
《GoodSync》是一款跨平台 (Windows/Mac/Linux/NAS/iOS/Android) 数据同步备份软件,可以自动将您的全部数据备份到多个目标位置,在需要的时候恢复数据轻松还原。当对某一处进行文件添加、更改或删除,则同步操作将对对应的 另一处的相关文件进行添加、更改和删除。相关文件将在两侧进行复制以确保两 处保持一致。
GoodSync 除了有同步功能外,同时提供分析、过滤,以及结果显 示等操作,以确保避免产生多余重复的文件并只对有需要的文件进行同步。借助专有文件传输协议 GoodSync Connect,可在您的所有设备(包括服务器、NAS 和手机)之间进行直接、快速、安全的 P2P 数据传输。
支持 NAS 设备(Western Digital、ASUSTOR、Synology、QNAP、Misc NAS)云存储(GoodSync 储存、Google Drive、Dropbox、Azure、Office 365、OneDrive、私有云、SharePoint、Box.com、Backblaze、Amazon S3)、协议和文件系统(FTP、SFTP、WebDAV、GoodSync Connect (GSTP)、SMB 共享、本地和远程网络)
最为推荐,简单易用免费,关键还好用!!!
《FreeFileSync》是一款免费开源的文件同步软件,支持多平台(Windows/Mac/Linux)、支持 FTP / SFTP 文件传输协议、支持对比检测文件、支持批处理自动同步文件、支持多种同步方案、支持排除文件筛选器、支持 Unicode (中文文件名)、支持命令行调用、支持区分大小写的同步。
教程:
MacOS 特有
https://apps.apple.com/us/app/sync-folders-pro/id522706442
https://www.greenworldsoft.com/
概要列表
Windows
PDF 专用
Drawboard PDF(已拥有,微软账号)
Drawboard 在 Win10 应用商店限时免费。Drawboard 更适合触摸屏和电磁笔手写,但是启动速度非常慢,文字渲染不够清晰。(支持手写的 PDF 阅读编辑器)
大名鼎鼎的 DRAWBOARD PDF,正价 88 元,有时候微软应用商店特价至 0 元,适合移动办公/SURFACE 平板人群使用。
万兴 PDF 专家(PDFelement),PDFelement 功能齐全、极其易用、界面美观,是目前(2020 年 4 月)用过的 PDF 软件中综合表现最好的。
嗨格式阅读器。小巧简洁,主打阅读。
非常好用!强烈推荐!!!!
Hello,各位小伙伴们好,又到周末了,给大家分享一款神器:『utools』。
官网及下载地址:https://u.tools/
uTools 是一个极简、插件化、跨平台的现代桌面软件。通过自由选配丰富的插件,打造你得心应手的工具集合。当你熟悉它后,能够为你节约大量时间,让你可以更加专注地改变世界。
utools 支持 Windows/Mac/Linux,
安装成功之后,可以通过快捷键『Alt+Space』,可以唤起 utools 窗口。
以下页面都是 mac 上截图,其他平台大同小异。

这个界面比较像 Alfred,刚开始没有安装任何插件,只能简单根据关键字查找系统中已安装的应用。

我们可以通过安装插件,扩展 『utools』的功能,提高我们的生产力。
相关插件都可以在插件中心安装,只需要在窗口输入插件,选择插件中心。
进入插件中心,选择安装相应的插件。
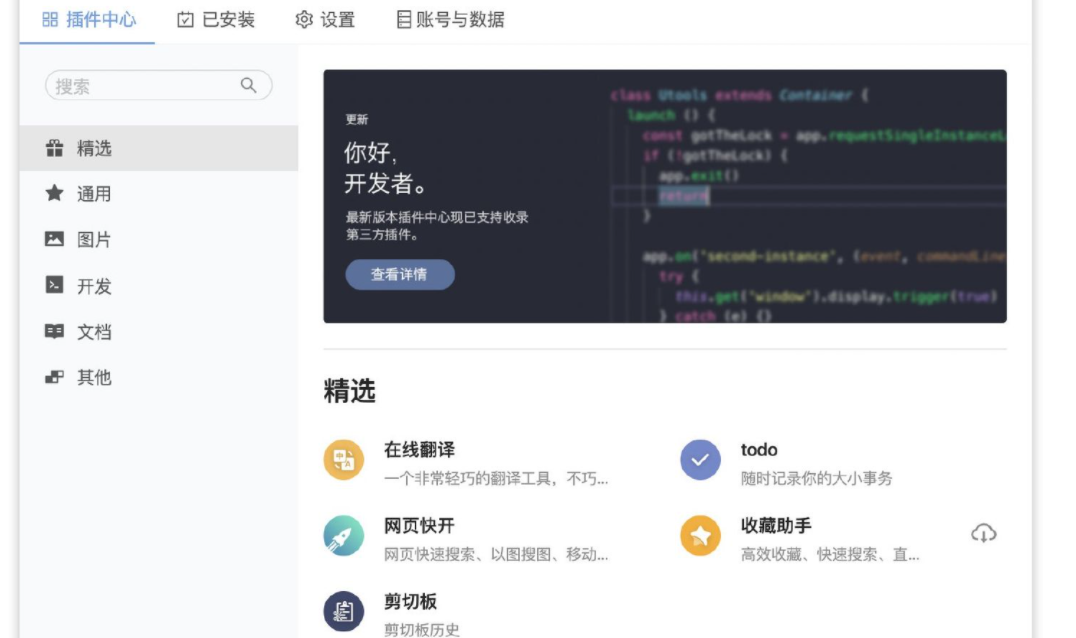
这个插件整合有道翻译、金山词霸、谷歌翻译、必应翻译。
关键字: translate/翻译
该插件可代替 Ditto
系统的剪贴板,只能查找最近一次的复制记录,这就比较麻烦。使用功能可以查找最近文本、图片、文件的复制记录,非常有用。
关键字:clipboard
这个功能么,聊天摸鱼神器,点击图片双击即可复制。
偷偷告诉你:很多骚表情都是可以从上面直接复制的。
关键字:doutu
通过这个插件,我们可以将复制过来的 Json 格式化,可以将 xml,yaml 转义成 json 。
关键字:json
日常开发经常遇到需要一些编码转化,比如 URL 编码。以前每次都需要谷歌搜个工具网页,现在直接使用这个插件就可以了。并且这个插件集合非常多转化小工具,
关键字:很多很多。。。。自己找吧!
base64
data/unixtime/timestamp
UUID/GUID
Hash 加密
URL

可以快速查找 Linux 命令使用方法,这真是极好的。
件中心还有很多插件,小伙伴们可以自行查找。没找到想要的插件,小伙伴也考虑自己开发。
用起来非常爽,完全可以代替电脑管家等扫描垃圾的软件。
收费,但可破解。到网盘找压缩包
如果弹出这个,说明 CleanMyPC 处于打开状态
再打开 Patch.exe,点击 patch 激活。出现下方红框字样,说明激活成功:
SpaceSniffer 是一款能够可视化分析磁盘空间占用情况的磁盘清理软件!免费,有用且可靠的,可以扫描 Windows PC 上的文件。使用此工具,可以清楚地了解计算机硬盘中文件和文件夹的结构。为了检查磁盘空间,该程序使用 Treemap 可视化布局,该布局使您可以基于颜色感知大型文件和文件夹在设备上的位置。 由于此磁盘清洁器速度很快,因此您可以在几秒钟内清楚地了解整体情况。只需单击一下,SpaceSniffer 便会详细显示所选文件,包括大小,文件名,创建日期等。
下载地址和官网为:http://www.uderzo.it/main_products/space_sniffer/
下载后得到一个 zip 压缩包,直接解压后以“管理员”的身份打开 exe 文件

打开后,选择要分析的目录,就可以很快地得到该目录的磁盘空间占用情况:
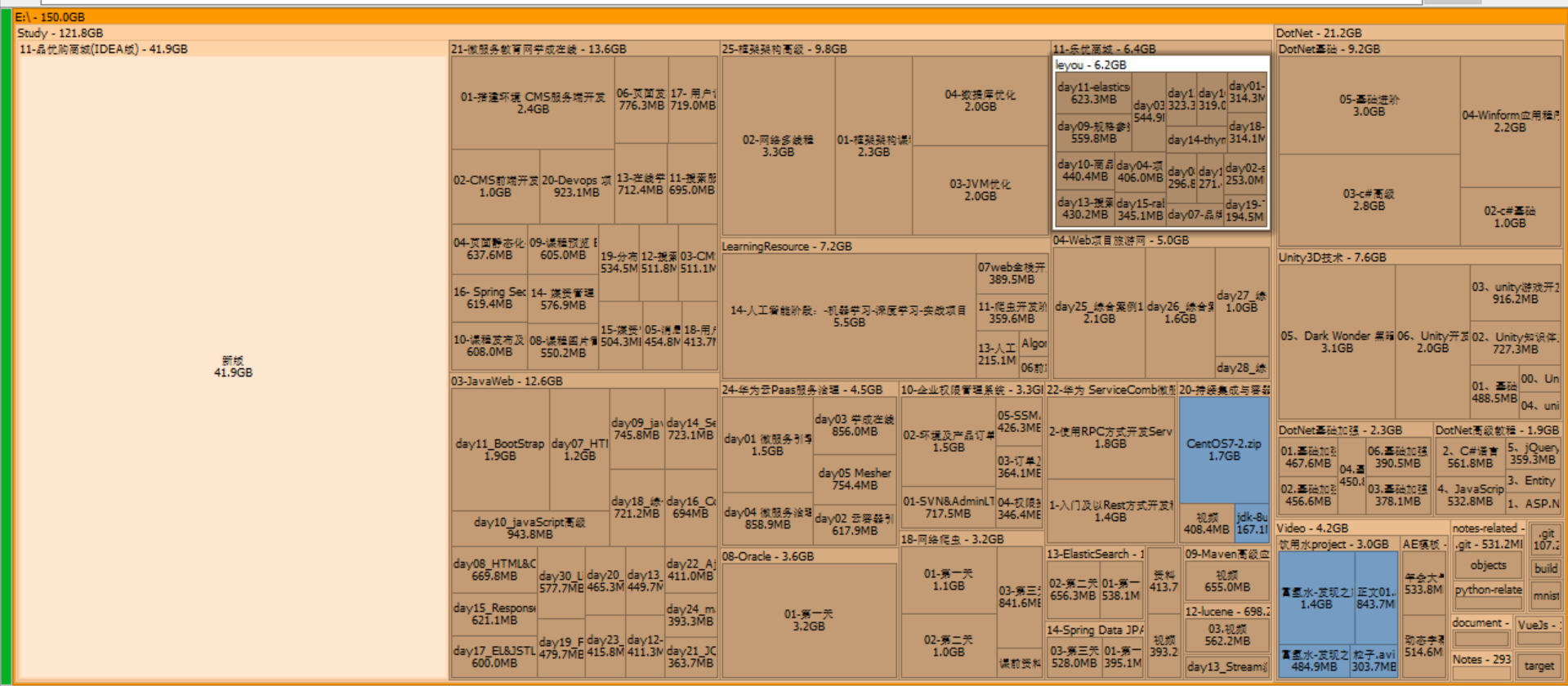
点击方格后,还会继续往下显示目录的磁盘占用情况,鼠标右键方格,则可以对该目录进行操作,打开、删除等等。
对电脑进行实时的性能监控
解决文件无法删除的问题
快速识别图片上的文字
解决 U 盘 弹出失败问题
恢复回收站删除的文件
做教程视频的时候是必须要用到录屏工具的,如果在 Windows 平台,那我的首选一定是这款来自韩国的 Bandicam,因为它简单易用,功能强大,并且没有花哨多余的附加项,是一款纯粹的录屏软件。
录屏功能比 Bandicam 要丰富、强大,但使用起来比 Bandicam 略复杂。
一般需求,使用 Bandicam 就足够了
https://github.com/BluePointLilac/ContextMenuManager
开源免费,非常方便地管理鼠标右键菜单,而不用自己去面对枯燥的注册表。
可能我们都知道,下载届有一个非常牛叉的神器:Inet Download Manager —— IDM。这个下载神器不仅支持多线程加速下载功能,还具备网页视频嗅探功能。当然,它还具备其他很多我尚未尝试过的功能,平时用得最多也就是这两个了,用过的也都说 nice,真香。
但在我切换到 macOS 系统后,发现 IDM 不兼容 macOS,所以找了一些可以替代 IDM 的下载器,最后发现有一款与 IDM 很相似的下载器,同样具备 IDM 那两个我个人常用的功能。这个下载器就是今天要介绍的:NDM
NDM(Neat Download Manager)这款软件完全免费无广告,支持 Windows 和 macOS
官方网站:https://www.neatdownloadmanager.com/index.php/en/
可以直接上官网下载,也可以通过以下链接下载:
链接: https://pan.baidu.com/s/1dxJHR0GhSgEGhGFTFEQ5rQ 提取码: sae6
安装后打开的界面如下:
这样子就可以使用了,APP 非常简洁。配合上浏览器插件,可以实现视频嗅探功能
给谷歌浏览器安装以下插件:

接着随便打开一个视频网站测试
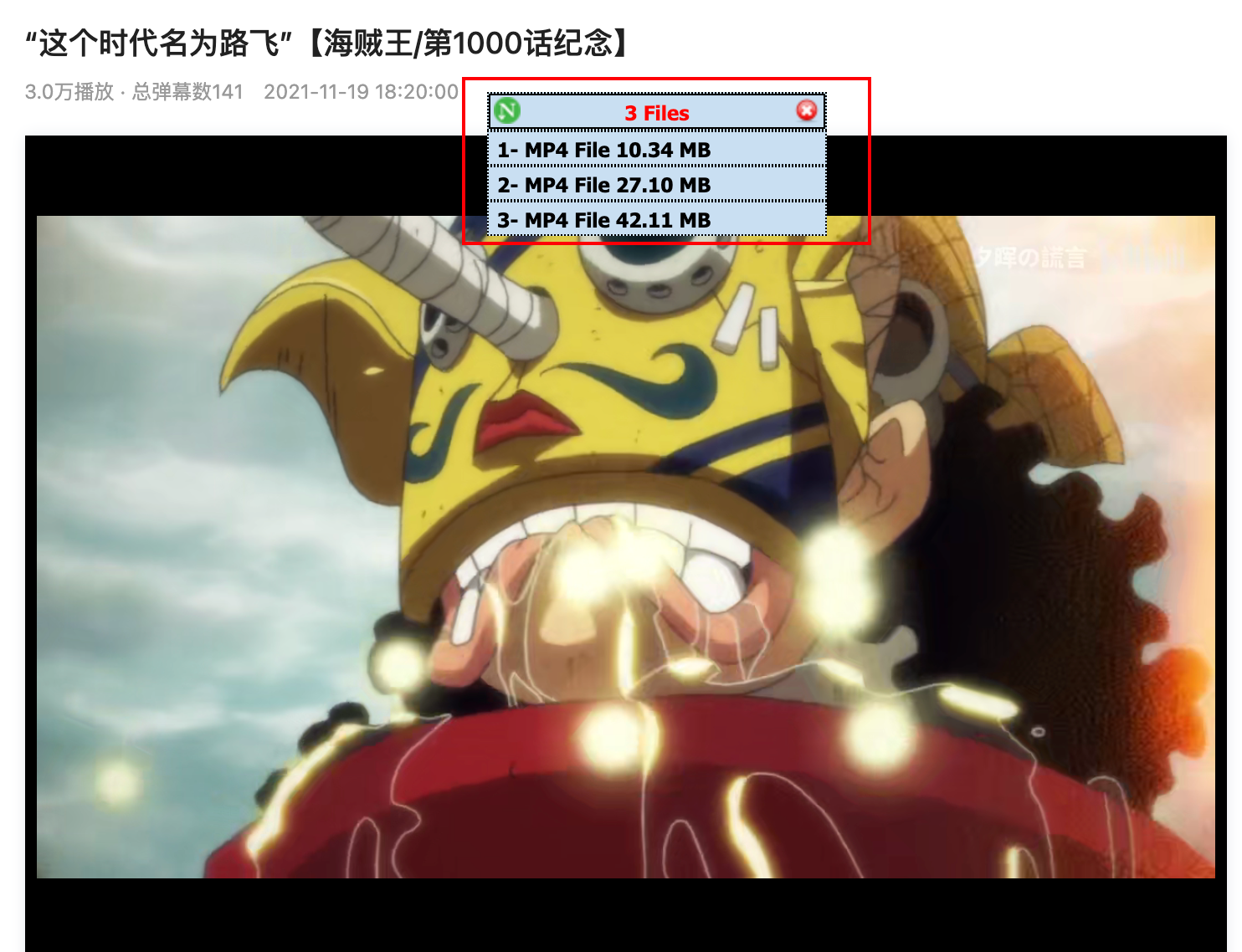
可以看到上面的红色方框中有三个可下载文件:1、2、3,视频越大,说明越高清。直接点击想要的清晰度视频,就可以实现下载。
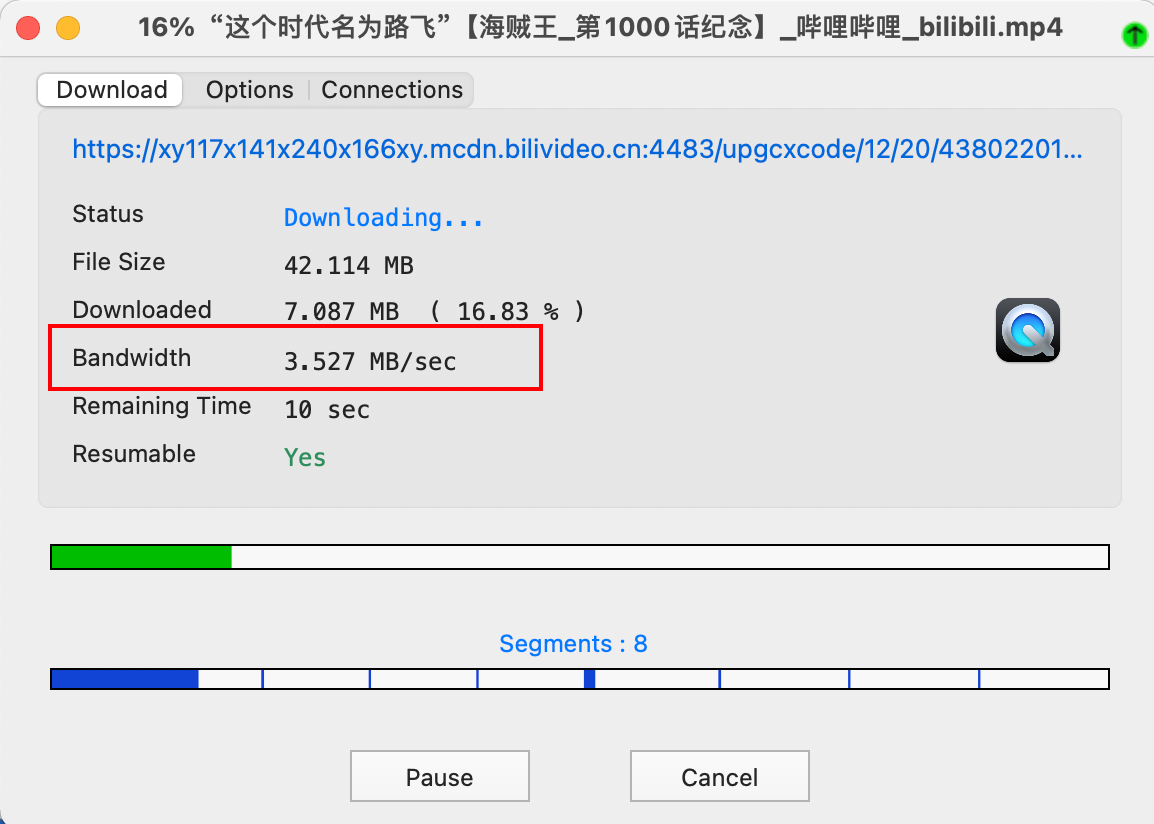
官网:https://github.com/qbittorrent/qBittorrent
下载地址:https://github.com/c0re100/qBittorrent-Enhanced-Edition/releases
种子与磁力链接的下载神器,推荐使用。
在 Windows 上如果迅雷不是很好用,可以用它来代替迅雷;在 MacOS 上可以用它来代替 Folx
专门用来下载视频的,支持很多主流网站视频的一键下载
跟 NDM 相比,NDM 属于通用型,Downie 属于专业性
不管是 NDM 还是 Downie 都无法下载磁链或 bt,所以还是需要 Folx、迅雷 或者 uTorrent 来补充
但个人使用后的感觉是 Folx 在 bt 搜索方面做得非常好,但是下载速度,且一言难尽,亦或者是个人配置问题,有哪位大佬知道的,能不能指导一下,不胜感激。
最强下载神器,除了不能下载磁链和 bt,其他都可以,速度飞快且稳定,配置还非常简单。
弥补 IDM 无法下载磁链和 bt 的不足。也可以用 Motrix 或 qBitTorren 等替换
蜈蚣文件是一款免费开源的下载神器,支持 Windows 和 Linux 平台(目前为 1.9 版本,暂不支持 Mac OS)
其官网为:http://www.filecxx.com/zh_CN/index.html
蜈蚣文件具备 IDM 和 NDM 的所有功能,而 IDM 和 NDM 所没有的功能但常用的,它也基本都有,例如 BT 下载、磁力链接下载等等。
同时,它还与 IDM 和 NDM 类似,支持在各个主流浏览器中安装插件,捕获下载链接,进行下载。
迅雷 + IDM
很多人都说 QBitTorrent 好,但是在一些冷门种子上,迅雷还是很能打的,QBitTorrent 下载不了的,迅雷也能下载。对于热门种子来说,两者的差异并不大。
蜈蚣文件的功能很全面,不仅能进行普通下载,也能下载种子,但是体验上,很多时候都没有速度,不是很行。
对于普通下载来说,在 Windows 上,IDM 还是最强的,虽然 NDM 也很强(两者功能相差无几),但是如果让我选,我选 IDM
NDM + qBitTorrent
因为 IDM 没有 MacOS 版本,所以只能用 NDM 代替
如果下载种子,则推荐用 QBitTorrent,Folx 说是 MacOS 上最强的种子下载神器,但在体验上,我并没有感受到(可能是因为在国内,亦或者是配置问题?)但是 Folx 提供了另一个很强大的功能:种子搜索。不过只能搜索国外的种子。总之,个人还是觉得 QBitTorrent 更好用些
Downie 更适合于专门下载视频的,如果需要时常从油管、B 站等这类网站上下载视频,那这个软件确实是神器,下载速度快、可批量、可自定义视频链接,还方便对下载下来的视频进行自动化后续处理。(如果简单的下载,NDM 和 IDM 也能做到)
为什么有 brew?因为 mac 平台的 appstore 非常的不好用,审核也很严,因此有很多一些大家公认的“正版”好用的软件,都会在 homebrew 发布,例如 openjdk、qq、maven、go 等,它是 Mac OSX 上的软件包管理工具,能够使用命令行实现安装、卸载、升级的功能。类似 ubuntu 系统下的 apt-get 的功能。而且很多软件都推荐使用 brew 安装,因为它可以帮助你解决安装依赖问题,例如你想下载 go、maven 这种命令行工具,你还需要配置其它的一些环境,而 brew 在安装的时候都帮你配置好了。
其中有个趣闻,就是 homebrew 作者因为不会白板翻转二叉树被 Google 拒了。笔者搜到 15 年的推特图。
- 命令行软件,例如 go、openjdk、maven、python 等。使用的基本命令为:
brew install openjdk
- 桌面端软件:例如 qq、微信、网易云音乐等桌面的软件。使用的基本命令为:
brew cask install qq,只是多了一个cask参数。
常见命令整理如下,以下命令都可带上 cask 参数:
brew search name:联网搜索软件是否存在 brew 中brew install name:安装软件brew upgrade name:更新软件brew uninstall name:卸载软件brew reinstall name:重新安装软件brew info name:查看软件安装地址brew cleanup:清理缓存等brew doctor:查看建议,例如升级等这是我的一个套装组合,各个都可以拆分来使用,但是它们组合使用效率极高。
iTerm2 是 macOS 的终端仿真器,支持一个界面有多个 session 等,你可以把它当做 SecureCRT 命令行版,但是支持各种自定义配置。
zsh 是 oh-my-zsh 的简称,我们默认都是用的 bash 终端,是不支持命令的自动填充高亮等。
json_pp 我主要是用来格式化 curl 命令行的结果,例如测试某个 restful 接口,返回的 json,在命令行就会自动给你格式化好输出,
brew 安装brew cask install iterm2brew install jsonpp当安装了 zsh 后,你可以在 vscode/idea 软件中切换默认的 shell
效果图如下,命令提示高亮,显示当前 git 分支
Mac 左上角的时间栏只能看当前时间不能看日历非常的不方便,因此有很多软件都支持左上角时间点击显示日历,但是 Itsycal 是我用过最方便轻量的免费软件,不仅可以同步日历的事件,而且各种小功能也非常的实用:
brew cask install itsycal没错,这个 QQ 就是我们平常用的 QQ 聊天软件。
在电脑截图上,我经常用的功能包括:滚动截长图,快速截图、识别图片中的文字、快速录个电脑操作视频。这些操作中,xnip 支持滚动截长图,我个人用了几款,虽然有好用的,但是都是收费的,而 xnip 免费版滚动截图只会有个水印。
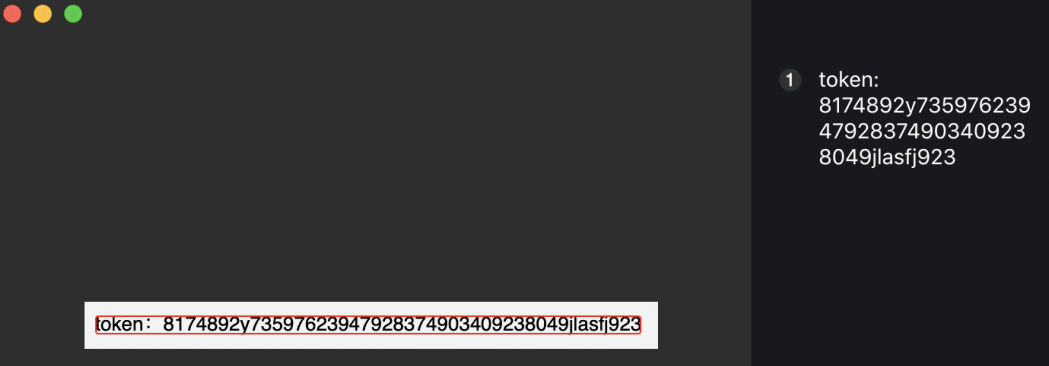
QQ 截图是结合截图、OCR 识别以及录视频为一体的超级功能!有时候发的截图里面的 token,或者手机号,又例如银行卡,就非常的方便,而且识别的非常准确!另外 qq 截图有个小技巧,截图双击时会截当前软件的边缘,不用自己手动拖拽。
QQ 截图 OCR 识别:
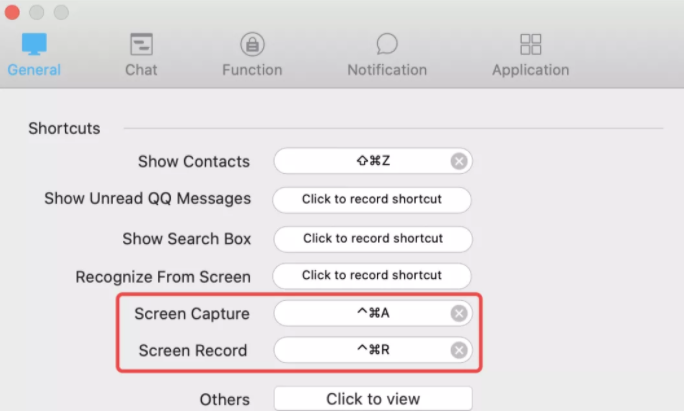
QQ 首选项配置截图、录制快捷键设置:
我的笔记之路,从白嫖有道云笔记,再到买了一年的印象笔记的高级会员,最后是买了阿里云服务器自制了蚂蚁笔记服务端,自己的笔记之路一路折腾,最后我发现还是语雀符合我对笔记知识整合的理解。本篇文章也同步发布在了语雀。
个人感觉语雀还是很香的!自己用来记笔记还是当做博客都是非常不错的选择。
腾讯柠檬清理,基本对标的就是 CleanMyMac,我个人没用过 CleanMyMac,但是感觉腾讯家的这个产品挺好用,在内测的时候就在一直用,产品在社区里面也一直听取用户的意见改进,持状态栏显示当前内存占用、网速等,对我来说是够用了。
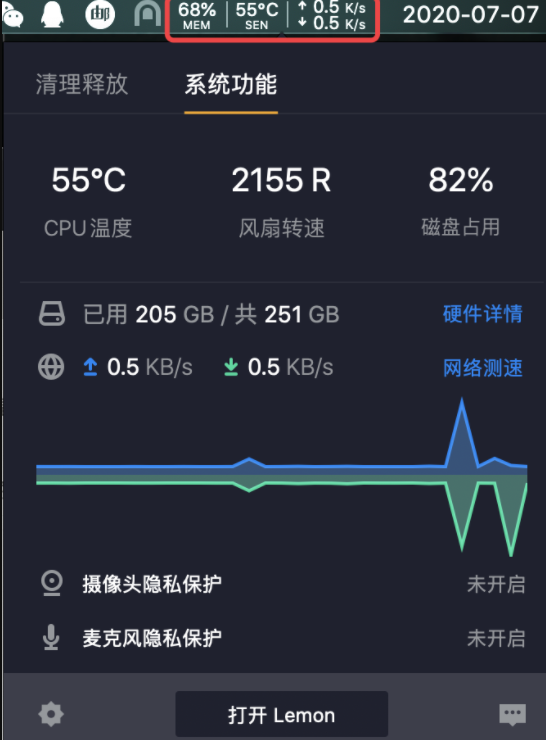
brew cask install tencent-lemon这个仅适合使用了阿里云 oss 的用户,它是快速的方便用户对自己 oss 进行操作管理,而且还有权限功能,我平常都是电脑截图,然后拖拽图片到 oss-brower 里面,接着获取地址。另外该产品是开源的,我开始很难相信这是阿里出的产品。
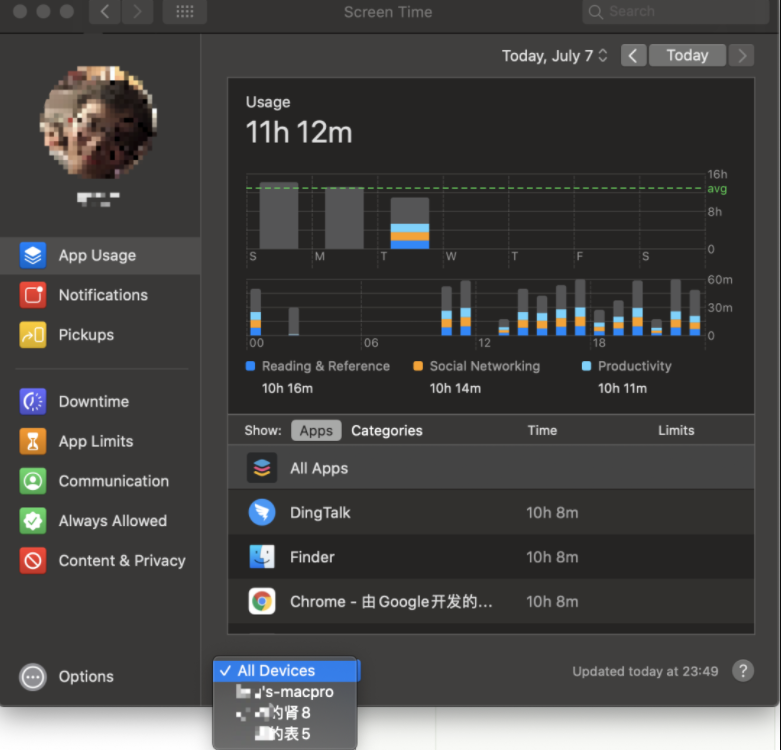
即 apple 自带的屏幕时间,大家有时候可能想知道,我在 Mac 和 Iphone 上使用各个软件的时候大概是多久,可能 Iphone 大家都知道,但是 Mac 大家可能不怎么关注,但是其实 Mac 的屏幕时间更加方便和强大,因为它根据 icloud 可以获取所有设备的总时间,或其它设备(例如 watch???)的使用时间。
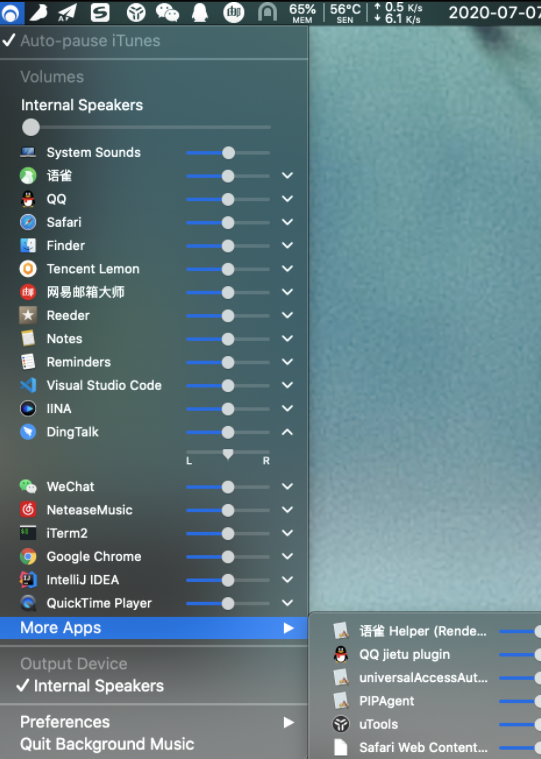
这个软件用于单独为每个软件设置独立的音量大小。属于你不装的时候挺好,装了之后就严重依赖它的软件。属于开源软件,社区活跃,更新也频繁,我使用过程中已知的 bug 主要是在开启和关闭过程中会没声音,不过我设置开机启动就好了。
brew cask install background-music可视化的 Redis 管理软件,开源软件。颜值高、功能多、作者更新快的可视化 Redis 管理软件。
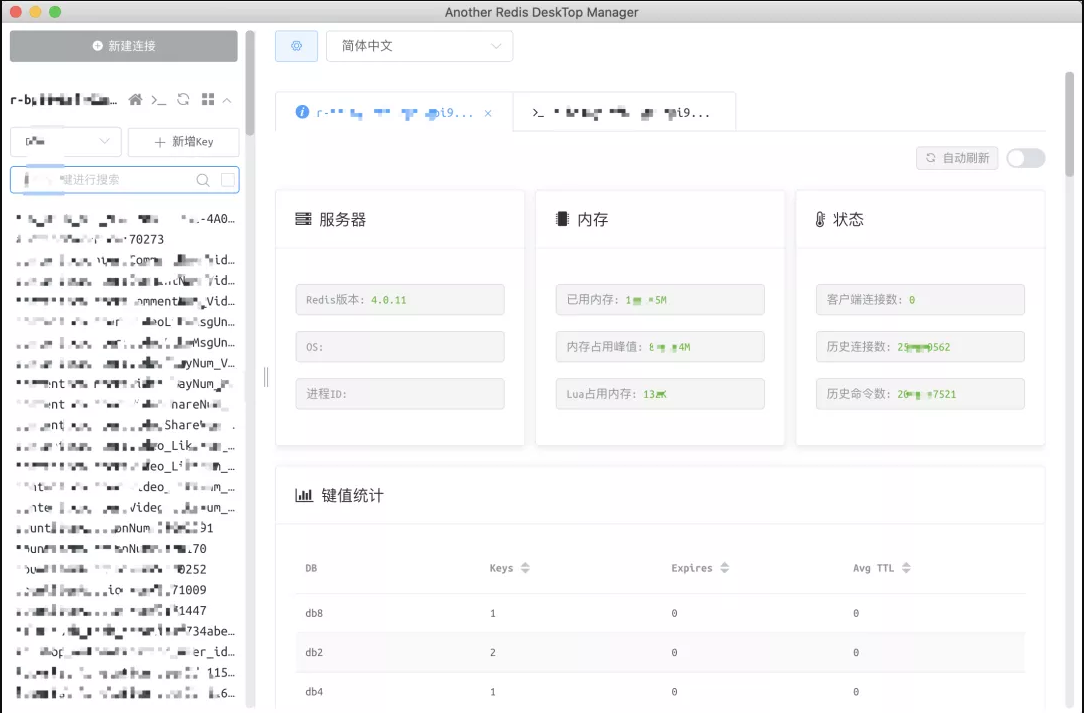
brew cask install another-redis-desktop-manager